闭包的深入理解
一:引子
|
|
|
|
|
|
乍一看这些本地变量已经不再受限于基本的域限制并拥有了无限的生命周期了。可以推出来的结论是:它们已经不是存在栈(stack)上,而是在堆(heap)上了
(Ps:对于heap和stack的区别有这么几点:1. stack的空间由操作系统自动分配和释放,heap的空间是手动申请和释放的,heap常用new关键字来分配;2. stack空间有限,heap的空间是很大的自由区。例如:在Java中,若只是声明一个对象,则先在栈内存中为其分配地址空间。若再new一下,实例化它,则在堆内存中为其分配地址;3. 举例:数据类型 变量名;这样定义的东西在栈区。如:Object a = null;这样定义的东西就在堆区:如:Object b = new Object();在堆内存中分配空间)
以上是文章摘要 阅读更多请点击——>右下角的more 以下是余下全文
二、理解闭包的工作环境
以如下代码理解:
|
|
- [ ] 通俗的理解:更透彻一些,所谓“闭包”,就是在构造函数体内定义另外的函数作为目标对象的方法函数,而这个对象的方法函数反过来引用外层函数体中的临时变量。这使得只要目标对象在生存期内始终能保持其方法,就能间接保持原构造函数体当时用到的临时变量值。尽管最开始的构造函数调用已经结束,临时变量的名称也都消失了,但在目标对象的方法内却始终能引用到该变量的值,而且该值只能通这种方法来访问。即使再次调用相同的构造函数,但只会生成新对象和方法,新的临时变量只是对应新 的值,和上次那次调用的是各自独立的。
- 从定义上看,所有的函数都可以是闭包。当一个函数调用时,引用了不是自己作用域内定义的变量(通常称其为自由变量),则形成了闭包;闭包是代码块和创建该代码块的上下文中数据的结合。
三、看闭包的微观世界
如果要更加深入的了解闭包以及函数a和嵌套函数b的关系,我们需要引入另外几个概念:
- 函数的执行环境(excution context)
- 活动对象(call object)
- 作用域(scope)
- 作用域链(scope chain)。
以函数a从定义到执行的过程为例阐述这几个概念
- 当定义函数a的时候,js编译器会将函数a的作用域链(scope chain)设置为定义a时a所在的“环境”,如果a是一个全局函数,则scope chain中只有window对象。
- 当执行函数a的时候,a会进入相应的执行环境(excution context)。
- 在创建执行环境的过程中,首先会为a添加一个scope属性,即a的作用域,其值就为第1步中的scope chain。即a.scope=a的作用域链。
- 然后执行环境会创建一个活动对象(call object)。活动对象也是一个拥有属性的对象,但它不具有原型而且不能通过JavaScript代码直接访问。创建完活动对象后,把活动对象添加到a的作用域链的最顶端。此时a的作用域链包含了两个对象:a的活动对象和window对象。
- 下一步是在活动对象上添加一个arguments属性,它保存着调用函数a时所传递的参数。
- 最后把所有函数a的形参和内部的函数b的引用也添加到a的活动对象上。在这一步中,完成了函数b的的定义,因此如同第3步,函数b的作用域链被设置为b所被定义的环境,即a的作用域。
到此,整个函数a从定义到执行的步骤就完成了。此时a返回函数b的引用给c,又函数b的作用域链包含了对函数a的活动对象的引用,也就是说b可以访问到a中定义的所有变量和函数。函数b被c引用,函数b又依赖函数a,因此函数a在返回后不会被GC回收。
对于执行b时的作用域链包含3个对象:b的活动对象、a的活动对象和window对象,如下图: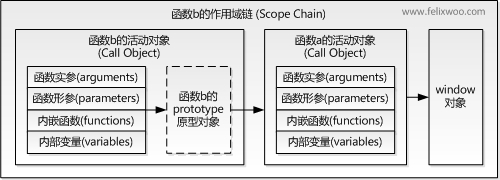
四:理解进堆的操作
这个过程涉及到这几个概念:
- 活动对象(AO)
- 变量对象(VO)
- 作用域链(scope chain)
- 执行上下文(EC)
1、作用域链:正是内部上下文所有变量对象(包括父变量对象)的列表
2、变量对象(Variable Object)、活动对象(Activation Object)
- 定义:每次当控制器转到JavaScript可执行代码的时候,即会进入到一个执行上下文(EC)。活动的执行上下文在逻辑上组成一个堆栈。堆栈底部永远都是全局上下文(global context),而顶部就是当前(活动的)执行上下文。堆栈在EC类型进入和退出上下文的时候被修改(进栈或出栈)。
我们定义一个EC的堆栈:ECStack = [];
ECStack = [
globalContext];
//GlobalContext始终在堆栈底部,其余的FunctionContext按激活顺序被压入,结束时弹出
|
|
【ps:每次进入function(即使function被递归调用或作为构造函数)的时候或内置的eval函数工作的时候,当前的执行上下文都会被压入堆栈】
浏览器在对代码进行解析时,会先进行变量声明和函数声明以及函数形参声明,这些优先声明的变量就会存储在变量对象(VO)中。
变量初始化的过程就是抽象变量对象VO的过程,对于活动对象的理解:
–》》全局上下文变量对象GlobalContextVO(VO === this === global)
–》》函数上下文变量对象FunctionContextVO
(VO === AO,并且添加了
ps:在函数执行上下文中,VO是不能直接访问的,此时又活动对象扮演VO的角色。(生成活动对象,将VO赋值给它)Arguments对象是活动对象的一个属性,它包括如下属性:1. callee–指向当前函数的引用;2.lenght–真正传递的参数个数;3.properties-indexes函数的参数值(按参数列表从左到右排列)。properties-indexs内部元素的个数等于arguments.length。properties-indexes的值和实际传递进来的参数之间是共享的。
3、整个执行流程
- 全局执行上下文;
创建global.VO - 全局变量的赋值 | 调用函数()–激活;
激活函数后,会得到当前的AO,其中有内部函数的声明、内部变量的声明、形参 - 进入所激活的函数的上下文;
进行所在作用域链上的变量的赋值、各种运算(作用链包含全局的VO和当前执行上下文的AO) - a、若在函数中有内部函数调用(或着执行),重复3;
- 4.b、若返回一个函数(或其引用),且该函数有对自由变量的引用–>形成闭包–>作用域链机制依然有效–>当前已压入执行上下文堆栈的FunctionContext不会出栈–>回到2
- 4.c、正常return或正常结束,FunctionContext出栈;–>回到2;
- 所有代码执行完毕,程序关闭,释放内存。
|
|
|
|
http://stackoverflow.com/questions/38626138/javascript-closurewhy-only-result3s-output-is-effected-by-nadd/38626232
这个网址是stackoverflow上我对上面代码疑惑的提问,几个大神的答案一综合就可以理解问题了,相当nice!!大家可以看一看。